

How To show Your Deepseek From Zero To Hero
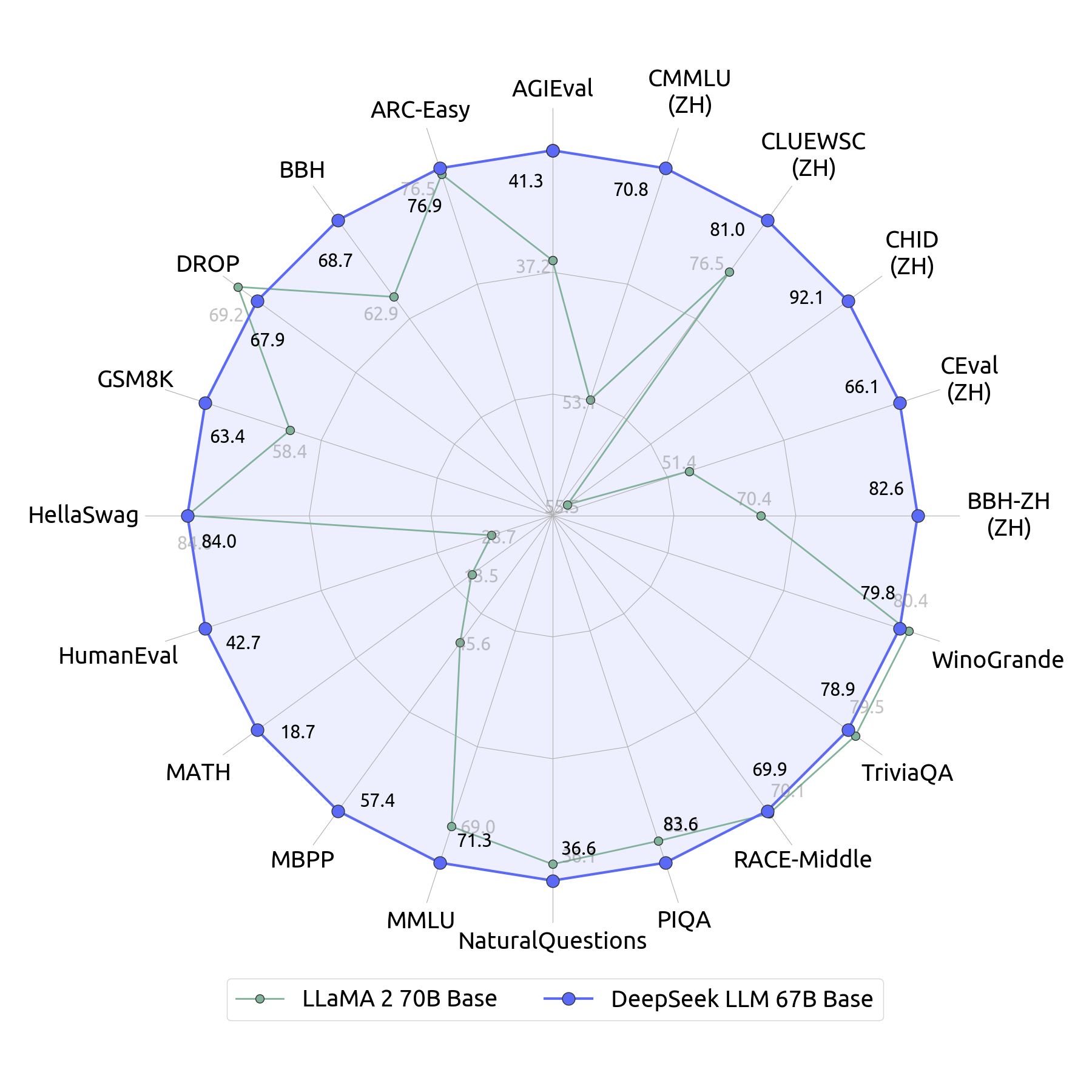
While its LLM could also be super-powered, DeepSeek appears to be pretty primary in comparison to its rivals relating to options. One in every of the principle options that distinguishes the deepseek ai china LLM household from different LLMs is the superior efficiency of the 67B Base model, which outperforms the Llama2 70B Base model in a number of domains, akin to reasoning, coding, arithmetic, and Chinese comprehension. By incorporating 20 million Chinese multiple-choice questions, DeepSeek LLM 7B Chat demonstrates improved scores in MMLU, C-Eval, and CMMLU. DeepSeek-V3, the latest model from Chinese AI agency DeepSeek, is making a big influence within the AI world. "Relative to Western markets, the associated fee to create excessive-quality information is decrease in China and there is a bigger talent pool with university skills in math, programming, or engineering fields," says Si Chen, a vice president at the Australian AI agency Appen and a former head of technique at both Amazon Web Services China and the Chinese tech giant Tencent. In Table 4, we present the ablation results for the MTP strategy. As well as to plain benchmarks, we additionally consider our fashions on open-ended era duties using LLMs as judges, with the results proven in Table 7. Specifically, we adhere to the unique configurations of AlpacaEval 2.Zero (Dubois et al., 2024) and Arena-Hard (Li et al., 2024a), which leverage GPT-4-Turbo-1106 as judges for pairwise comparisons.
 What DeepSeek has shown is that you can get the identical results without using people at all-at least more often than not. Instead of utilizing human suggestions to steer its fashions, the firm uses feedback scores produced by a pc. The agency launched V3 a month in the past. But, apparently, reinforcement studying had an enormous impression on the reasoning model, R1 - its impression on benchmark efficiency is notable. Second, Monte Carlo tree search (MCTS), which was used by AlphaGo and AlphaZero, doesn’t scale to normal reasoning tasks because the issue house is not as "constrained" as chess and even Go. Notably, this is a more challenging job because the input is a basic CFG. This overlap ensures that, because the model additional scales up, so long as we maintain a constant computation-to-communication ratio, we are able to still employ fine-grained specialists across nodes whereas attaining a near-zero all-to-all communication overhead." The fixed computation-to-communication ratio and close to-zero all-to-all communication overhead is putting relative to "normal" methods to scale distributed training which sometimes simply means "add more hardware to the pile".
What DeepSeek has shown is that you can get the identical results without using people at all-at least more often than not. Instead of utilizing human suggestions to steer its fashions, the firm uses feedback scores produced by a pc. The agency launched V3 a month in the past. But, apparently, reinforcement studying had an enormous impression on the reasoning model, R1 - its impression on benchmark efficiency is notable. Second, Monte Carlo tree search (MCTS), which was used by AlphaGo and AlphaZero, doesn’t scale to normal reasoning tasks because the issue house is not as "constrained" as chess and even Go. Notably, this is a more challenging job because the input is a basic CFG. This overlap ensures that, because the model additional scales up, so long as we maintain a constant computation-to-communication ratio, we are able to still employ fine-grained specialists across nodes whereas attaining a near-zero all-to-all communication overhead." The fixed computation-to-communication ratio and close to-zero all-to-all communication overhead is putting relative to "normal" methods to scale distributed training which sometimes simply means "add more hardware to the pile".
However, prior to this work, FP8 was seen as efficient but much less efficient; DeepSeek demonstrated how it can be used successfully. However, GRPO takes a rules-primarily based rules method which, while it will work better for issues that have an objective answer - reminiscent of coding and math - it would struggle in domains the place solutions are subjective or variable. However, it could still be used for re-rating top-N responses. To prepare its fashions to answer a wider range of non-math questions or perform artistic duties, DeepSeek nonetheless has to ask folks to provide the feedback. I'm still unsure about this, I'm altering my views rather a lot proper now. Here’s one other favourite of mine that I now use even greater than OpenAI! The DeepSeek workforce writes that their work makes it potential to: "draw two conclusions: First, distilling more highly effective fashions into smaller ones yields glorious outcomes, whereas smaller models counting on the big-scale RL talked about in this paper require enormous computational power and should not even achieve the efficiency of distillation.
 " DeepSeek’s group wrote. For example, they used FP8 to considerably scale back the quantity of reminiscence required. For example, it refuses to discuss Tiananmen Square. This chopping-edge approach considerably slashes inference prices by a powerful 93.3% by lowered utilization of key-value (KV) caching, representing a serious leap toward price-effective AI options. This not only improves computational efficiency but also considerably reduces coaching prices and inference time. Combining these efforts, we obtain excessive training efficiency." This is a few seriously deep work to get the most out of the hardware they had been restricted to. In other phrases, they made decisions that might enable them to extract essentially the most out of what they had obtainable. "Skipping or slicing down on human feedback-that’s a giant thing," says Itamar Friedman, a former research director at Alibaba and now cofounder and CEO of Qodo, an AI coding startup primarily based in Israel. The V3 paper says "low-precision coaching has emerged as a promising resolution for environment friendly training". The V3 paper also states "we also develop environment friendly cross-node all-to-all communication kernels to totally make the most of InfiniBand (IB) and NVLink bandwidths. "As for the coaching framework, we design the DualPipe algorithm for environment friendly pipeline parallelism, which has fewer pipeline bubbles and hides a lot of the communication during coaching by way of computation-communication overlap.
" DeepSeek’s group wrote. For example, they used FP8 to considerably scale back the quantity of reminiscence required. For example, it refuses to discuss Tiananmen Square. This chopping-edge approach considerably slashes inference prices by a powerful 93.3% by lowered utilization of key-value (KV) caching, representing a serious leap toward price-effective AI options. This not only improves computational efficiency but also considerably reduces coaching prices and inference time. Combining these efforts, we obtain excessive training efficiency." This is a few seriously deep work to get the most out of the hardware they had been restricted to. In other phrases, they made decisions that might enable them to extract essentially the most out of what they had obtainable. "Skipping or slicing down on human feedback-that’s a giant thing," says Itamar Friedman, a former research director at Alibaba and now cofounder and CEO of Qodo, an AI coding startup primarily based in Israel. The V3 paper says "low-precision coaching has emerged as a promising resolution for environment friendly training". The V3 paper also states "we also develop environment friendly cross-node all-to-all communication kernels to totally make the most of InfiniBand (IB) and NVLink bandwidths. "As for the coaching framework, we design the DualPipe algorithm for environment friendly pipeline parallelism, which has fewer pipeline bubbles and hides a lot of the communication during coaching by way of computation-communication overlap.
Should you have any concerns with regards to exactly where along with the way to work with ديب سيك, you can e-mail us with our own web-page.
Reviews